Unicode kodēšana: rakstzīmju kodēšanas standarts
Katrs interneta lietotājs mēģinavienu vai otru tās funkciju vismaz reizi redzēt uz displeja, kas rakstīts latīņu burtiem, vārds "Unikoda". Kas tas ir, jūs mācīsities, lasot šo rakstu.

Definīcija
"Unicode" kodēšana ir kodēšanas standartsrakstzīmes. To ierosināja bezpeļņas organizācija Unicode Inc. 1991. gadā. Standarts ir paredzēts vienā dokumentā apvienot pēc iespējas vairāk dažādu veidu simbolus. Tajā izveidotā lapa var saturēt dažādu valodu (no krievu uz korejiešu valodu) un hieroglifus un matemātiskās zīmes. Visas šī kodējuma rakstzīmes tiek parādītas bez jebkādām problēmām.
Iemesli radīšanai
Reiz ilgu laiku pirms vienotas sistēmas rašanās"Unikoda" kodējums tika izvēlēts, pamatojoties uz dokumenta autora izvēli. Šī iemesla dēļ bieži vien lasot vienu dokumentu, jums bija jāizmanto dažādas tabulas. Dažreiz tas bija jādara vairākas reizes, kas ievērojami sarežģīja parastā lietotāja dzīvi. Kā jau minēts, šīs problēmas risinājumu 1991. gadā ierosināja bezpeļņas organizācija Unicode Inc., kas piedāvāja jaunu rakstzīmju kodēšanas veidu. Viņš tika aicināts apvienot morāli novecojušos un daudzveidīgos standartus. "Unikoda" - kodēšana, kas tajā laikā ļāva sasniegt neiedomājamus: izveidot rīku, kas atbalsta lielu skaitu rakstzīmju. Rezultāts pārsniedza daudzas cerības - parādījās dokumenti, kas vienlaikus saturēja gan angļu, gan krievu valodas tekstu, latīņu un matemātiskās izteiksmes.
Bet pirms tam izveidoja vienu kodējumunepieciešamība risināt vairākas problēmas, kas radušās tādēļ, ka tajā laikā pastāvēja ļoti dažādi standarti. Visbiežāk tie ir:
- elfi raksti vai "karkozyabry";
- ierobežots rakstzīmju kopa;
- konversijas kodēšanas problēma;
- fontu dublēšanās.

Īss vēsturisks noiets
Iedomājieties, ka pagalmā ir 80. Datortehnoloģijas nav tik plaši izplatītas un atšķirīgas no mūsdienām. Tajā laikā katra operētājsistēma ir unikāla savā veidā, un katrs entuziasts tos pabeidz īpašām vajadzībām. Informācijas apmaiņas nepieciešamība kļūst par pasaules visjaunāko pārskatīšanu. Mēģinot lasīt dokumentu, kas izveidots citā OS, ekrānā bieži parādās nesaprotams rakstzīmju kopums, un spēles ar kodējumu sākas. Tas ne vienmēr ir iespējams ātri izdarīt, un dažreiz nepieciešamo dokumentu var atvērt sešus mēnešus vēlāk vai vēlāk. Cilvēki, kuri bieži apmainās ar informāciju, paši izveido reklāmguvumu tabulas. Un šeit darbs uz tiem atklāj interesantu detaļu: tās ir jāizveido divos virzienos: "no manis līdz tavai" un atpakaļ. Lai veiktu banālu inversiju aprēķinos mašīna nevar, jo tajā labajā ailē ir avota kods, un kreisajā slejā - rezultāts, bet jebkurā veidā gluži pretēji. Ja dokumentā vajadzēja izmantot jebkādas īpašas rakstzīmes, tās vispirms bija jāpievieno, un pēc tam arī partnerim tika paskaidrots, kas viņam vajadzēja darīt, lai šīs rakstzīmes netiktu pārvērstas par "krakozyabry". Un neaizmirsīsim, ka katrai kodēšanai mums bija jāattīsta vai jāīsteno savi fonti, kā rezultātā OS tika izveidots milzīgs dublētu skaits.
Iedomājieties arī, ka fontu lapā jūs esatJūs redzēsiet 10 identiskus Times New Roman vārdus ar maziem apzīmējumiem: UTF-8, UTF-16, ANSI, UCS-2. Tagad jūs saprotat, ka universāla standarta izstrāde bija neatliekama nepieciešamība?

"Tēvu radītāji"
"Unicode" izveides pirmsākumi meklējami 1987. gadāgadā, kad Xerox Džo Bekers kopā ar Lee Kolinsu un Apple Mark Davis sāka pētīt universālā rakstzīmju kopuma praktisko izveidi. 1988. Gada augustā Joe Becker publicēja projektu priekšlikumam izveidot 16 bitu starptautisku daudzvalodu kodēšanas sistēmu.
Dažus mēnešus vēlāk, Unicode darba grupatika paplašināts, iekļaujot arī Ken Whistler un Mike Kernegan no RLG, Glenn Wright no Sun Microsystems un vairākiem citiem speciālistiem, kas ļāva pabeigt darbu pie iepriekšēja vienotā kodēšanas standarta izveidošanas.

Vispārējs apraksts
Unicode ir balstīta uz simbola jēdzienu. Šī definīcija tiek saprasta kā abstrakta parādība, kas pastāv konkrētā rakstīšanas formā un realizēta ar grafēmām (tās "portreti"). Katrs raksturs ir iestatīts Unicode ar unikālu kodu, kas pieder konkrētam standarta blokam. Piemēram, grafte B ir gan angļu, gan krievu alfabetēs, bet Unicode tā atbilst 2 dažādām rakstzīmēm. Tie tiek pārvērsti mazos burtos, ti, katrs no tiem ir aprakstīts ar datu bāzes atslēgu, īpašību kopumu un pilnu nosaukumu.
Unikoda priekšrocības
No citiem laikabiedētājiem, kas kodē "Unicode"atšķīrās no lielas simbolu "šifrēšanas" zīmju rezerves. Fakts ir tāds, ka viņa priekšgājējiem bija 8 biti, tas ir, viņi atbalstīja 28 rakstzīmes, bet jaunajā attīstībā jau bija 216 rakstzīmes, kas bija milzīgs solis uz priekšu. Tas ļāva kodēt gandrīz visus esošos un sadalītos alfabētos.
Ar Advent "Unicode" vairs nav nepieciešamsizmantojiet reklāmguvumu tabulas: tā kā vienots standarts vienkārši nullificē to vajadzību. Tāpat "krakozyabry" arī izzuda aizmirstībā - vienots standarts padarīja tos neiespējamus, kā arī likvidēja nepieciešamību izveidot dublētus fontus.
Unikoda izstrāde
Protams, progress nenotiek, un no brīžaPirmā prezentācija jau ir pagājusi 25 gadus. Tomēr Unicode kodēšana spītīgi saglabā savu pozīciju pasaulē. Daudzējādā ziņā tas bija iespējams tāpēc, ka tas kļuva viegli īstenojams un izplatīts, to atzīst patentētas (maksas) un atvērtā pirmkoda programmatūras izstrādātāji.
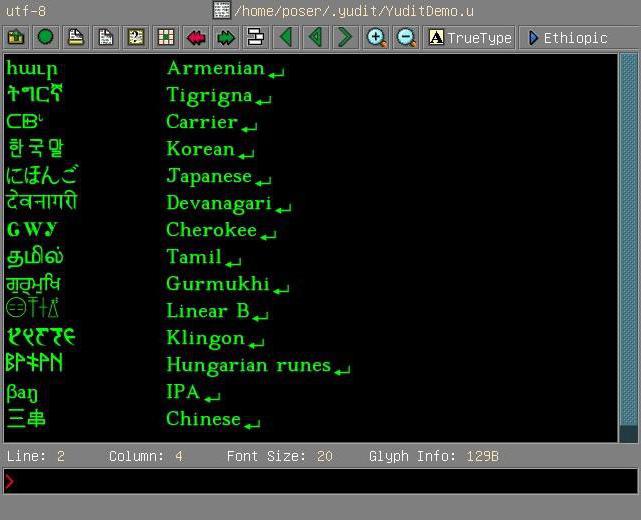
Šajā gadījumā nav jāuzskata, ka šodien mēstā pati Unicode kodēšana ir pieejama pirms ceturtdaļas pirms gadsimta. Tajā brīdī, tas tika aizstāts ar versiju 5.h.h, un skaits kodēto simbolu, ir pieaudzis līdz 231. Par iespēju izmantot lielāku rezervi zīmes atteicās joprojām saglabāt atbalstu Unicode-16 (kodējumu, kur maksimālo daudzumu viņu ierobežotā skaitā 216). Kopš tās pirmsākumiem, un līdz versijai 2.0.0 "Unicode standarts" ir palielinājusi rakstzīmju skaitu, ka tas, kas iekļautas gandrīz 2 reizes. Iespēju izaugsme turpinājās nākamajos gados. Līdz 4.0.0 versijai jau bija nepieciešams palielināt pašu standartu, kas tika izdarīts. Rezultātā Unicode ir ieguvis formu, kādā mēs to šodien pazīstam.

Kas vēl ir Unicode?
Papildus milzīgajam, pastāvīgi papildinošamrakstzīmju skaits, "Unikoda" - teksta informācijas kodēšana ir vēl viena noderīga funkcija. Mēs runājam par tā saukto normalizāciju. Nevis ritinātu visu dokumentu raksturu pa raksturs, un aizstāt ikonas atbilstības tabulu, izmantot kādu no esošajiem normalizācijas algoritmiem. Par ko mēs runājam?
Tā vietā, lai izniekotu skaitļošanas resursusmašīnas, lai regulāri pārbaudītu to pašu simbolu, kas var būt līdzīgs dažādos alfabētos, izmanto īpašu algoritmu. Tas ļauj jums izņemt līdzīgas rakstzīmes atsevišķā skatījumu tabulas grafikā un jau atzīt tās, nevis atkārtoti pārbaudīt visus datus.
Ir izstrādāti un īstenoti četri šādi algoritmi. Katrs konversija notiek stingri noteiktā principa, atšķiras no otras puses, tāpēc, lai izsauktu kāds no tiem nav efektīvākais iespējams. Katrs tika izstrādāts īpašām vajadzībām, tika ieviests un veiksmīgi izmantots.

Standarta izplatība
25 gadu vēsturē "Unikoda"visticamāk saņēma vislielāko izplatību pasaulē. Saskaņā ar šo standartu tiek koriģētas arī programmas un tīmekļa lapas. Pieteikumu plašumu var minēt tas, ka šodien Unicode izmanto vairāk nekā 60% interneta resursu.
Tagad jūs zināt, kad parādījās standarta "Unicode". Kas tas ir, jūs arī zināt un varēsiet novērtēt visu izgudrojuma vērtību, ko izstrādājusi Unicode Inc. speciālistu grupa. vairāk nekā pirms 25 gadiem.
</ p>




